

001 什么是冒泡排序?
冒泡排序是在遍历数组的过程中,每次都要比较连续相邻的元素,如果某一对相邻元素是降序(即前面的数大于后面的数),则互换它们的值,否则,保持不变。由于较大的值像“气泡”一样逐渐浮出顶部,而较小的值沉向底部,所以叫冒泡排序。
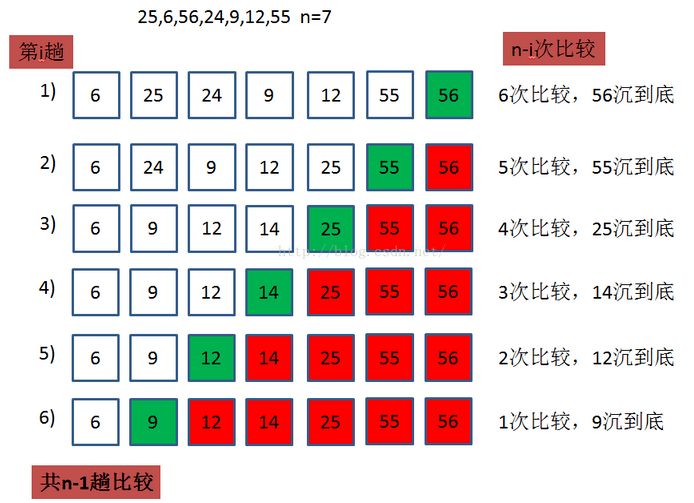
002 冒泡排序的代码实现?
具体实现参考如下源代码:
//冒泡排序
public static void bubbleSort(int[] list){
int n=list.length;
for(int i=1;i<n;i++){//总共比较n-1趟
for(int j=0;j<n-i;j++){//第i趟比较n-i次
if(list[j]>list[j+1]){
int temp;
temp=list[j];
list[j]=list[j+1];
list[j+1]=temp;
}
}
System.out.print("第"+(i)+"轮排序结果:");
display(list);
}
}
003 冒泡排序时间复杂度?
冒泡排序的时间复杂度是O(N2)。 假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢? N-1次!因此,冒泡排序的时间复杂度是O(N2)。
004 冒泡排序稳定性?
冒泡排序是稳定的算法,它满足稳定算法的定义。所谓算法稳定性指假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
005 冒泡排序的改进版实现。
/*
* 冒泡排序(改进版)
*
* 参数说明:
* a -- 待排序的数组
* n -- 数组的长度
*/
public static void bubbleSort2(int[] a, int n) {
int i, j;
int flag; // 标记
for (i = n - 1; i > 0; i--) {
flag = 0; // 初始化标记为0
// 将a[0...i]中最大的数据放在末尾
for (j = 0; j < i; j++) {
if (a[j] > a[j + 1]) {
// 交换a[j]和a[j+1]
int tmp = a[j];
a[j] = a[j + 1];
a[j + 1] = tmp;
flag = 1; // 若发生交换,则设标记为1
}
}
if (flag == 0)
break; // 若没发生交换,则说明数列已有序。
}
}
006 什么是选择排序?
选择排序是在遍历一个待排序的数组过程中,
第一次从 arr[0] 到 arr[n-1] 中选取最小值,与 arr[0] 交换;
第二次从arr[1] 到 arr[n-1]中选取最小值, 与arr[1]交换;
第三次从arr[2] 到 arr[n-1]中选取最小值,与arr[2]交换;
……
第 i 次从 arr[i-1] 到 arr [n-1] 中选取最小值,与arr[i-1]交换;
第n-1次从 arr[n-2] 到 arr [n-1] 中选取最小值,与 arr[n-2] 交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列。
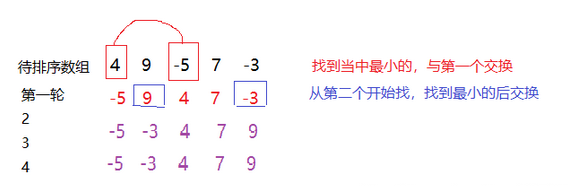
007 选择排序的代码实现?
具体实现参考如下源代码:
public static void choice(int arr[]) {
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
int min = arr[i];
for (int j = i + 1; j < arr.length; j++) {
if (min > arr[j]) {
min = arr[j];
minIndex = j;
}
}
if (minIndex != i) {
arr[minIndex] = arr[i];
arr[i] = min;
}
}
}
008 有一组数据“12,15,1,18,2,35,30,11”,用选择法由小到大排序,第2趟交换数据后数据的顺序是( )。
A. 11,1,2,12,35,18,30,15
B. 1,2,12,18,15,35,30,11
C. 1,2,11,12,15,18,30,35
D. 1,2,11,12,15,18,35,30
答案:B
解析:第一趟选择1,将1和12交换位置,序列变为1,15,12,18,2,35,30,11,第二趟选择2,将2和15交换位置,序列变为1,2,12,18,15,35,30,11;故B正确
009 在选择排序中,以下什么情况下选择排序会更快执行?
A. 数据已按升序排列
B. 数据已按升降序排列
C. 俩者花费时间一样
答案:C
解析:不管升序还是降序 其比较次数都是整条路径。
010 什么是插入排序?
1)插入排序是把n个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
2)具体流程如下:
【1】把数组分成有序a[0]和无序a[1~7]范围,有序中就一个数肯定是有序的不用管。
【2】把数组分成有序a[0~1]和无序a[2~7]范围,有序中让a[1]和a[0]范围比较,如果a[1]大于a[0],不用交换;如果a[1]小于a[0],交换位置,这样a[0~1]就是有序的。
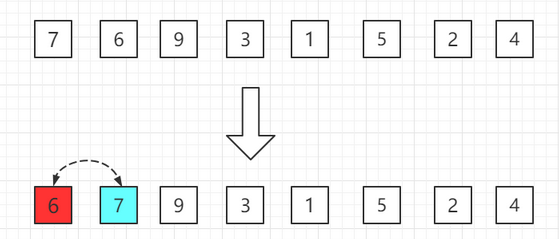
【3】把数组分成有序a[0~2]和无序a[3~7]范围,有序中让a[2]和a[0~1]范围比较。如果a[2]大于a[1],不用交换;如果a[2]小于a[1],交换位置;周而复始再让a[1]和a[0]比较,这样a[0~2]就是有序的。

【4】把数组分成有序a[0~3]和无序a[4~7]范围,有序中让a[3]和a[0~2]范围比较。如果a[3]大于a[2],不用交换;如果a[3]小于a[2],交换位置;周而复始再让a[2]和a[1]比较........这样a[0~3]就是有序的。
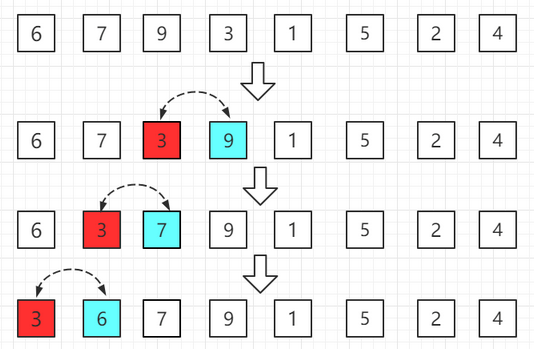
【5】把数组分成有序a[0~4]和无序a[5~7]范围,有序中让a[4]和a[0~3]范围比较。如果a[4]大于a[3],不用交换;如果a[4]小于a[3],交换位置;周而复始再让a[3]和a[2]比较........这样a[0~4]就是有序的。
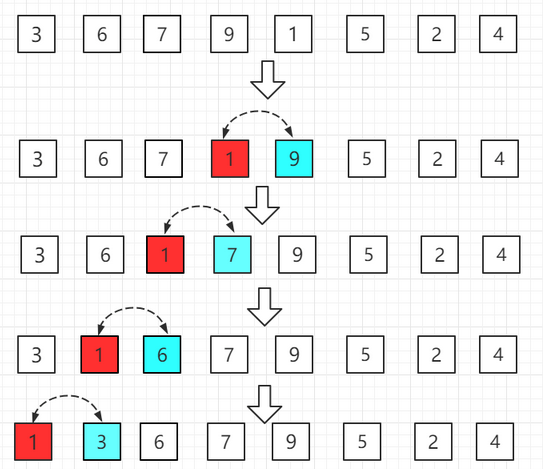
...... 就这样依次比较到最后一个元素,通俗的说就是一路向左交换。
011 插入排序的代码实现?
public static void insertSort(int[ ] arr){
if(arr==null||arr.length<2){
return;
}
//0~0有序的
//0~i有序
for(int i=1;i<arr.length;i++){
for(int j=i-1;j>=0&&arr[j]>arr[j+1];j--){
swap(arr,j,j+1);
}
}
}
012 设一组初始记录关键字的长度为8,则最多经过( )趟插入排序可以得到有序序列。
A. 6
B. 7
C. 8
D. 9
答案:B
解析:第i趟插入排序可以使前i个元素为n个元素中前i小且有序,执行n-1次后前n-1个元素为n个元素中前n-1小且有序,第n个元素同时也处于正确的位置,故只需n-1趟插入排序。
013 什么是希尔排序?
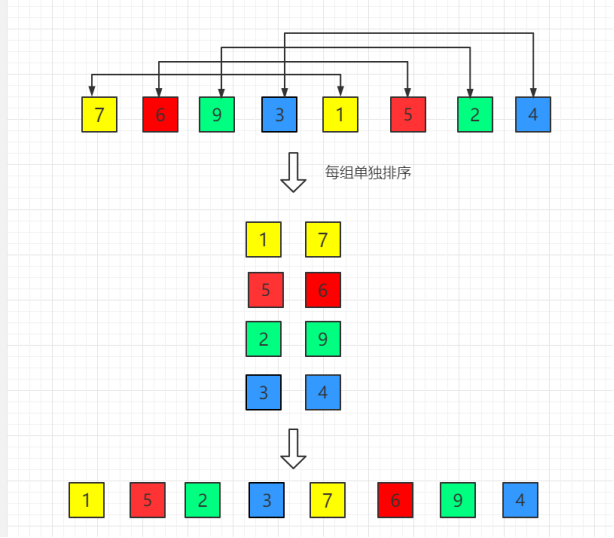
1)希尔排序又称递减增量排序算法,是插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。希尔排序目的为了加快速度改进了插入排序,交换不相邻的元素对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。在此我们选择增量 gap=length/2,缩小增量以 gap = gap/2 的方式,用序列 {n/2,(n/2)/2...1} 来表示。
2) 算法图解
【1】下面数组的长度length为8,初始增量第一趟 gap = length/2 = 4,即让第1个数和第5个数比较,第2个数和第6个数进行比较,第3个数和第7个数进行比较,第4个数和第8个数进行比较,最终结果是【1 5 2 3 7 6 9 4】
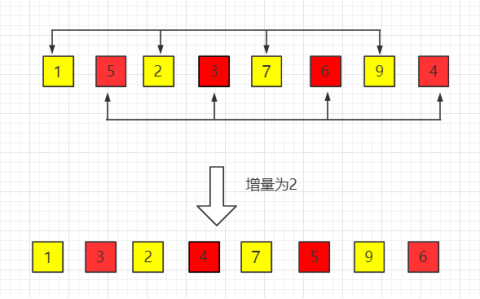
【2】第二趟,gap=gap/2=2,增量缩小为 2。即让第1个数、第3个数、第5个数和第7个数进行比较,第2个数、第4个数、第6个数和第8个数进行比较,最终结果是【1 3 2 4 7 5 9 6】
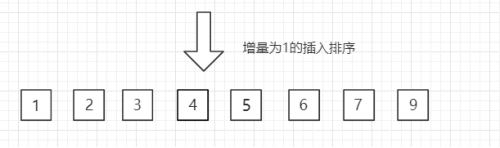
【3】第三趟,gap=gap/2=1,增量缩小为 1。所有的数进行比较得到的结果【1 2 3 4 5 6 7 9】
014 希尔排序的代码实现?
public static void shellSort(int[] args) {
for (int gap = args.length / 2; gap > 0; gap /= 2) {
// 从第gap个元素,逐个对其所在组进行直接插入排序操作
for (int i = gap; i < args.length; i++) {
int j = i;
int temp = args[j];
if (args[j] < args[j - gap]) {
while (j - gap >= 0 && temp < args[j - gap]) {
// 移动法
args[j] = args[j - gap];
j -= gap;
}
args[j] = temp;
}
}
}
}
015 希尔排序的组内排序采用的是( )。
A. 直接插入排序
B. 折半插入排序
C. 快速排序
D. 归并排序
答案: A
解析: 希尔排序的思想是:先将待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成),分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
016 设 一组初始记录关键字序列为(50,40,95,20,15,70,60,45),则以增量d=4的一趟希尔排序结束后前4条记录关键字为( )。
A. 40,50,20,95
B. 15,40,60,20
C. 15,20,40,45
D. 45,40,15,20
答案: B
解析:希尔排序属于插入类排序,是将整个有序序列分割成若干小的子序列分别进行插入排序。排序过程是先取一个正整数d1<n,把所有序号相隔d1的数组元素放一组,组内进行直接插入排序;然后取d2<d1,重复上述分组和排序操作;直至di = 1,即所有记录放进一个组中排序为止。
题目中:d = 4,排序之后为:15,40,60,20,50,70,95,45
d = 2,排序之后为:15,20,50,40,60,45,95,70
d = 3,排序之后为:15,20,40,45,50,60,70,95
017 什么是归并排序?
1)归并排序采用了分治策略(divide-and-conquer),就是将原问题分解为一些规模较小的相似子问题,然后递归解决这些子问题,最后合并其结果作为原问题的解。
2)算法图解
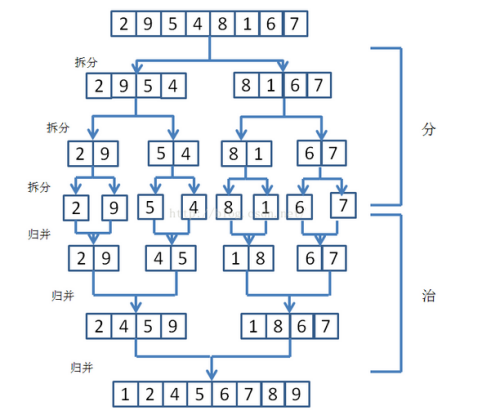
【1】如图:先将数组分两半,左边是【2、9、5、4】,右边是【8、1、6、7】;
【2】将左边【2、9、5、4】继续分两半,左边是【2、9】,右边是【5、4】;
【3】将【2、9】继续分两半,左边是【2】,右边是【9】;将【5、4】继续分两半,左边是【5】,右边是【4】;
【5】创建临时辅助数组,将左边【2】和右边【9】通过比较大小进行合并【2、9】;
【6】创建临时辅助数组,将左边【5】和右边【4】通过比较大小进行合并【4、5】;
【7】创建临时辅助数组,将左边【2、9】和右边【4、5】通过比较大小进行合并【2、4、5、9】,同样的道理得到【1、8、6、7】;
【8】创建临时辅助数组,将左边【2、4、5、9】和右边【1、8、6、7】通过比较大小进行合并【1、2、4、5、6、7、8、9】;
018 归并排序的代码实现?
public static void mergeSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
process(arr, 0, arr.length - 1);
}
public static void process(int[] arr, int L, int R) {
if (L == R) {
return;
}
int mid = L + ((R - L) >> 1);
process(arr, L, mid);
process(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int M, int R) {
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M + 1;
while (p1 <= M && p2 <= R) {
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= M) {
help[i++] = arr[p1++];
}
while (p2 <= R) {
help[i++] = arr[p2++];
}
for (i = 0; i < help.length; i++) {
arr[L + i] = help[i];
}
}
019 关于归并排序叙述正确的是( ).
A. 归并排序使用了分治策略的思想
B. 归并排序使用了贪心策略的思想
C. 子序列的长度一定相等
D. 归并排序是稳定的
答案:AD
解析:暂无解析
020 若外部存储上有3110400个记录,做6路平衡归并排序,计算机内存工作区能容纳400个记录,则排序好所有记录,需要作几趟归并排序( )
A. 6
B. 3
C. 5
D. 4
答案:C
解析:每次将工作区装满,共计3110400/400=7776个归并段,对于n路归并排序,m个归并段,需要归并排序的次数为次,代入数据得到答案为5,所以C正确。
021 什么是快速排序?
1)快排问题和荷兰国旗问题类似,快速排序采用的思想是分治思想。主要分两个步骤:
第一步:从要排序的数组中随便找出一个元素作为基准(pivot),然后对数组进行分区操作,使基准左边元素的值都不大于基准值,基准右边的元素值都不小于基准值。
第二步就是对高段位和地段为两部分进行递归排序。
2)算法图解
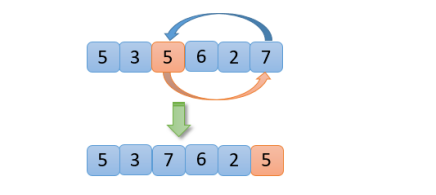
【1】从【5,3,5,6,2,7】数组中,随机选取一个数(假设这里选的数是5)与最右边的7进行交换 ,如下图
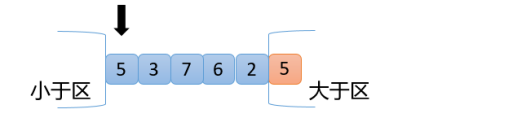
【2】准备好以5为分界点,三个区域分别为小于区、大于区(大于区包含最右侧的一个数)和等于区,并准备一个指针,指向最左侧的数,如下图
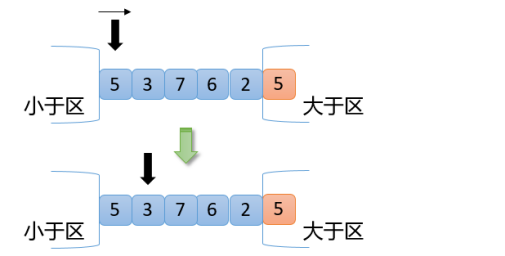
【3】接下来,每次操作都拿指针位置的数与5进行比较,交换原则如下:
原则1:指针位置的数<5
拿指针位置的数与小于区右边第一个数进行交换
小于区向右扩大一位
指针向右移动一位
原则2:指针位置的数=5
指针向右移动一位
原则3:指针位置的数>5
拿指针位置的数与大于区左边第一个数进行交换
大于区向左扩大一位
指针位置不动
根据图可以看出指针指向的第一个数是5,5=5,满足交换原则2,指针向右移动一位,如下图
【4】从上图可知,此时3<5,根据交换原则第1点,拿3和5(小于区右边第一个数)交换,小于区向右扩大一位,指针向右移动一位,结果如下图
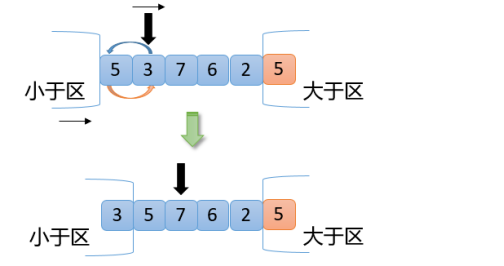
【5】从上图可以看出,此时7>5,满足交换原则第3点,7和2(大于区左边第一个数)交换,大于区向左扩大一位,指针不动,如下图
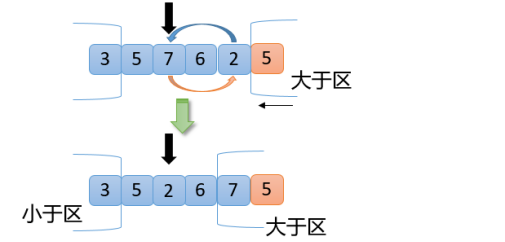
【6】从上图可以看出,2<5,满足交换原则第1点,2和5(小于区右边第一个数)交换,小于区向右扩大一位,指针向右移动一位,得到如下结果
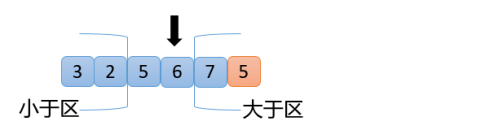
【7】从上图可以看出,6>5,满足交换原则第3点,6和6自己换,大于区向左扩大一位,指针位置不动,得到下面结果
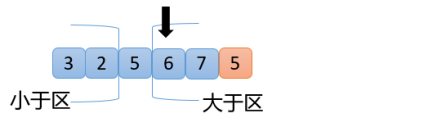
【8】此时,指针与大于区相遇,则将指针位置的数6与随机选出来的5进行交换,就可以得到三个区域:小于区,等于区,大于区,周而复始完成最终的排序
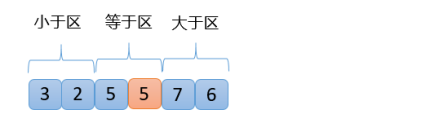
022 快速排序的代码实现?
public static void quickSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
quickSort(arr, 0, arr.length - 1);
}
// arr[l..r]排好序
public static void quickSort(int[] arr, int L, int R) {
if (L < R) {
swap(arr, L + (int) (Math.random() * (R - L + 1)), R);
int[] p = partition(arr, L, R);
quickSort(arr, L, p[0] - 1); // < 区
quickSort(arr, p[1] + 1, R); // > 区
}
}
// 这是一个处理arr[l..r]的函数
// 默认以arr[r]做划分,arr[r] -> p <p ==p >p
// 返回等于区域(左边界,右边界), 所以返回一个长度为2的数组res, res[0] res[1]
public static int[] partition(int[] arr, int L, int R) {
int less = L - 1; // <区右边界
int more = R; // >区左边界
int index=L;
while (index < more) { // L表示当前数的位置 arr[R] -> 划分值
if (arr[index] < arr[R]) { // 当前数 < 划分值
swap(arr, ++less, index++);
} else if (arr[index] > arr[R]) { // 当前数 > 划分值
swap(arr, --more, index);
} else {
index++;
}
}
swap(arr, more, R);
return new int[] { less + 1, more };
}
023 快速排序时间复杂度?
快速排序的时间复杂度在最坏情况下是O(N2),平均的时间复杂度是O(N*lgN)。
假设被排序的数列中有N个数。遍历一次的时间复杂度是O(N),需要遍历多少次呢? 至少lg(N+1)次,最多N次。 为什么最少是lg(N+1)次? 快速排序是采用的分治法进行遍历的,我们将它看作一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。因此,快速排序的遍历次数最少是lg(N+1)次。 为什么最多是N次? 这个应该非常简单,还是将快速排序看作一棵二叉树,它的深度最大是N。因此,快读排序的遍历次数最多是N次。
024 快速排序稳定性?
快速排序是不稳定的算法,它不满足稳定算法的定义。
025 什么是堆排序?
堆结构如下图,堆的实际结构是数组,但是我们在分析它的时候用的是有特殊标准的完全二叉树来分析。也就是说数组是堆的实际物理结构而完全二叉树是我们便于分析的逻辑结构。堆有两种:大根堆和小根堆。每个节点的值都大于其左孩子和右孩子节点的值,称为大根堆。每个节点的值都小于其左孩子和右孩子节点的值,称为小根堆。
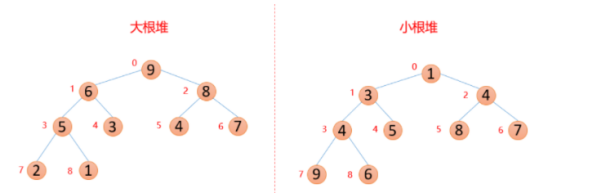
上面的结构映射成数组就变成了下面这个样子

026 堆排序的特点?
1.首先堆的大小是提前知道的,根节点的位置上存储的数据总是在数组的第一个元素。
2.假设一个非根节点所存储的数据的索引为i,那么它的父节点存储的数据所对应的索引就为[(i-1)/2]
3.假设一个节点所存储的数据的索引为i,那么它的孩子(如果有)所存储的数据分别所对应的索引为:左孩子是[2*i+1],右孩子是[2*i+2]
027 堆排序的流程?
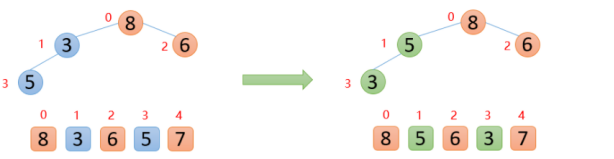
第一步,将待排序的数组构造成一个大根堆,假设有下面这个数组:

具体思路:第一次保证0~0位置大根堆结构,第二次保证0~1位置大根堆结构,第三次保证0~2位置大根堆结构...直到保证0~n-1位置大根堆结构(每次新插入的数据都与其父节点进行比较,如果插入的数比父节点大,则与父节点交换。周而复始一直向上比较,直到小于等于父节点或者来到了根节点则终止)
【1】插入6的时候,6大于他的父节点3,即arr(1)>arr(0),则交换;此时保证了0~1位置是大根堆结构,如下图:
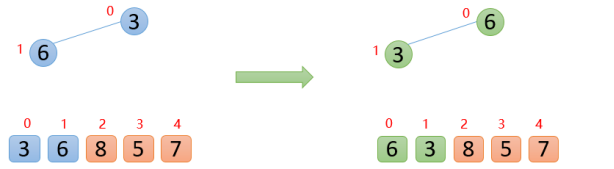
【2】插入8的时候,8大于其父节点6,即arr(2)>arr(0),则交换;此时,保证了0~2位置是大根堆结构,如下图
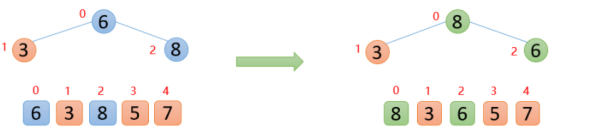
【3】插入5的时候,5大于其父节点3,则交换,交换之后,5又发现比8小,所以不交换;此时,保证了0~3位置大根堆结构,如下图
【4】插入7的时候,7大于其父节点5,则交换,交换之后,7又发现比8小,所以不交换;此时整个数组已经是大根堆结构
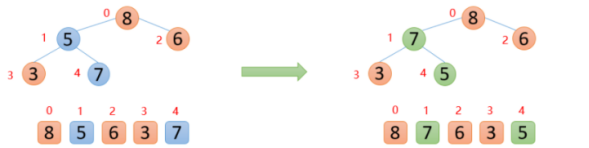
第二步,将根节点的数与末尾的数交换
【1】大根堆中整个数组的最大值就是堆结构的父节点,接下来将根节点的数8与末尾的数5交换

第三步,将剩余的n-1个数再构造成大根堆
如上图所示,此时最大数8已经来到末尾,让堆的有效大小减1,后面拿顶端的数与其左右孩子较大的数进行比较,如果顶端的数大于其左右孩子较大的数,则停止,如果顶端的数小于其左右孩子较大的数,则交换;周而复始一直向下比较,直到大于左右孩子较大的数或者没有孩子节点则终止。
下图中,5的左右孩子中,左孩子7比右孩子6大,则5与7进行比较,发现5<7,则交换;交换后,发现5已经大于他的左孩子,说明剩余的数已经构成大根堆,

第四步,再将第二步和第三步反复执行,便能得到有序数组
028 如何将待排序的数组构造成一个大根堆?
首先遍历该数组,假设某个数处于index位置,每次都让index位置和父节点位置的数进行比较,如果大于父节点的值就交换位置,....周而复始,一直到不能往上为止。
for (int i = 0; i < arr.length; i++) { // O(N)
while (arr[index] > arr[(index - 1) / 2]) {
swap(arr, index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
029 如何将剩余的n-1个数再构造成大根堆?
先将大根堆的头节点的数据与堆上的最后一个数交换位置后,把堆有效区的长度减1,再从头节点开始做向下的比较,每次都和左右孩子中较大值进行比较,如果父节点比最大孩子的值下就交换位置....周而复始,一直到不能往下为止。
// 某个数在index位置,能否往下移动
public static void heapify(int[] arr, int index, int heapSize) {
int left = index * 2 + 1; // 左孩子的下标
while (left < heapSize) { // 下方还有孩子的时候
// 两个孩子中,谁的值大,把下标给largest
int largest = left + 1 < heapSize && arr[left + 1] > arr[left] ? left + 1 : left;
// 父和较大的孩子之间,谁的值大,把下标给largest
largest = arr[largest] > arr[index] ? largest : index;
if (largest == index) {
break;
}
swap(arr, largest, index);
index = largest;
left = index * 2 + 1;
}
}
030 堆的排序如何实现?
具体实现前面的问题,具体源代码实现如下:
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//第一步,将待排序的数组构造成一个大根堆
for (int i = 0; i < arr.length; i++) { // O(N)
heapInsert(arr, i); // O(logN)
}
int heapSize = arr.length;
//第二步,将根节点的数与末尾的数交换
swap(arr, 0, --heapSize);
while (heapSize > 0) { // O(N)
//第三步,将剩余的n-1个数再构造成大根堆
heapify(arr, 0, heapSize); // O(logN)
//第二步,将根节点的数与末尾的数交换
swap(arr, 0, --heapSize); // O(1)
}
}
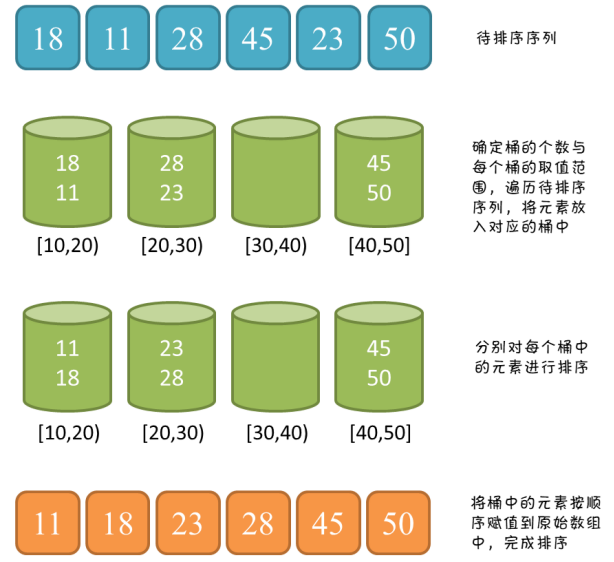
031 什么是桶排序?
1)桶排序(Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶里。每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序),最后依次把各个桶中的记录列出来记得到有序序列。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,他不受到O(n log n)下限的影响。
2)算法图解
032 堆排序平均执行的时间复杂度和需要附加的存储空间复杂度分别是( )
A. O(n^2)和O(1)
B. O(nlog(n))和O(1)
C. O(nlog(n))和O(n)
D. O(n^2)和O(n)
答案:B
解析:暂无解析
033 什么是计数排序?
1)计数排序不是一个基于比较的排序算法。它是用一个数组来统计每种数字出现的次数,然后按照大小顺序将其依次放回原数组。但是计数排序有一个很严重的问题,就是其只能对整数进行排序,一旦遇到字符串时,就无能为力了。
2 )算法图解
第一步:找出原始数组【0,2,5,3,7,9,10,3,7,6】中元素值最大的,记为max=10。

第二步:创建一个计数数组count,数组长度是max值加1,其元素默认值都为0。

第三步:遍历原始数组中的元素,以原始数组中的元素作为计数数组count的索引,以原始数组中的元素出现次数作为计数数组count的元素值。下图可以得到原始数组【0,2,5,3,7,9,10,3,7,6】中元素0出现1次,元素2出现1次,元素3出现2次,元素5出现1次,元素6出现1次,元素7出现2次,元素9出现1次,元素10出现1次。

第四步:遍历计数数组count,找出其中元素值大于0的元素,将其对应的索引作为元素值填充到结果数组result中去,每处理一次,计数数组count中的该元素值减1,直到该元素值不大于0,依次处理计数数组count中剩下的元素。
034 计数排序的代码实现?
public static void countSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int[] bucket = new int[max + 1];
for (int i = 0; i < arr.length; i++) {
bucket[arr[i]]++;
}
int i = 0;
for (int j = 0; j < bucket.length; j++) {
while (bucket[j]-- > 0) {
arr[i++] = j;
}
}
}
035 桶排序的代码实现?
public static void bucketSort(int[] arr){
// 计算最大值与最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
// 计算桶的数量
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 将每个元素放入桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
// 对每个桶进行排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
// 将桶中的元素赋值到原序列
int index = 0;
for(int i = 0; i < bucketArr.size(); i++){
for(int j = 0; j < bucketArr.get(i).size(); j++){
arr[index++] = bucketArr.get(i).get(j);
}
}
}
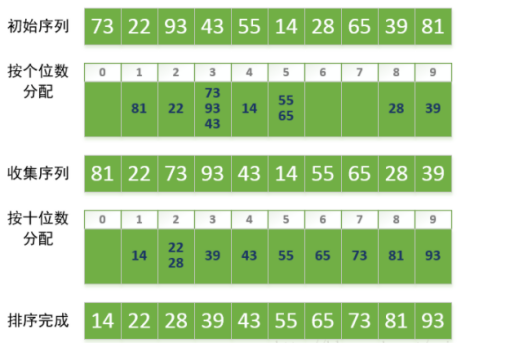
036 什么是基数排序?
1)基数排序是对桶排序的一种改进,这种改进是让“桶排序”适合于更大的元素值集合的情况,而不是提高性能。它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
2)算法图解
第一步,将所有待比较数值根据个位数的数值分别分配至编号0到9的桶中;
第二步,桶中数据根据先进先出的原则出来,收集完整的序列;
第三步,十位、百位....周而复始
037 基数排序的代码实现?
//digit代表最大的数有几个十进制位
public static void radixSort(int[] arr, int L, int R, int digit) {
//十进制数
final int radix = 10;
int i = 0, j = 0;
// 有多少个数准备多少个辅助空间
int[] bucket = new int[R - L + 1];
for (int d = 1; d <= digit; d++) { // 有多少位就循环几次
//十进制的数,创建长度为10的数组
int[] count = new int[radix]; // count[0..9]
for (i = L; i <= R; i++) {
j = getDigit(arr[i], d);//获取该数的个位、十位、百位......上的数
count[j]++;//获取数组中每个数每位分别是1、2、3....9数分别总共有几个
}
for (i = 1; i < radix; i++) {
//获取数组中每个数每位分别是<=1、<=2、<=3....<=9数分别总共有几个
count[i] = count[i] + count[i - 1];
}
for (i = R; i >= L; i--) {
j = getDigit(arr[i], d);//获取该数的个位、十位、百位......上的数
bucket[count[j] - 1] = arr[i];//将数放回到辅助空间
count[j]--;
}
for (i = L, j = 0; i <= R; i++, j++) {
arr[i] = bucket[j];
}
}
}
//获取该数的个位、十位、百位......上的数
public static int getDigit(int x, int d) {
return ((x / ((int) Math.pow(10, d - 1))) % 10);
}
038 什么是时间复杂度?
时间复杂度指执行这个算法需要消耗多少时间,也可以认为是对排序数据的总的操作次数。常见的时间复杂度有:常数阶O(1),对数阶O(log2n),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n2)。
//时间复杂度O(1)
sum = n*(n+1)/2;
//时间复杂度O(n)
for(int i = 0; i < n; i++){
System.out.println("%d ",i);
}
//时间复杂度O(n^2)
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++){
System.out.println("%d ",i);
}
}
//运行次数为(1+n)*n/2//时间复杂度O(n^2)
for(int i = 0; i < n; i++){
for(int j = i; j < n; j++){
System.out.println("%d ",i);
}
}
//设执行次数为x. 2^x = n 即x = log2n,时间复杂度O(log2n)
int i = 1, n = 100;
while(i < n){
i = i * 2;
}
039 常见的时间复杂度排序?
O(1)< O(logn)<O(n)<O(nlog2n)<O(n2)<O(n3)<…<O(2n)<O(n!)
040 空间复杂度是什么?
空间复杂度是指算法在计算机内执行时所需存储空间的度量,它也是问题规模n的函数
常见的空间复杂度有:常量空间复杂度O(1)、对数空间复杂度O(log2N)、线性空间复杂度O(n)。
041 时间复杂度和空间复杂度关系?
对于一个算法来说,空间复杂度和时间复杂度往往是相互影响的。当追求一个较好的时间复杂度时,可能会使空间复杂度的性能变差,即可能导致占用较多的存储空间;反之,当追求一个较好的空间复杂度时,可能会使时间复杂度的性能变差,即可能导致占用较长的运行时间。有时我们可以用空间来换取时间以达到目的。
042 什么是算法稳定性?
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。排序算法是否为稳定的是由算法具体实现决定的。总体上,堆排序、快速排序、希尔排序、直接选择排序不是稳定的排序算法,而冒泡排序、直接插入排序、归并排序、基数排序、计数排序、桶排序是稳定的排序算法。
043 比较排序和非比较排序的区别?
比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。如冒泡排序、选择排序、插入排序、归并排序、堆排序、快速排序
非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。 如计数排序、基数排序、桶排序
044 十大排序的复杂度及稳定性?
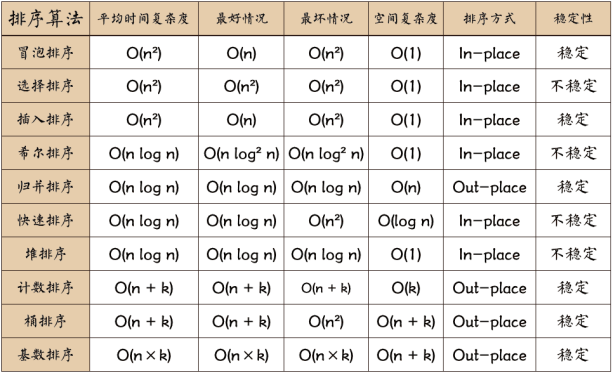
045 下列哪种排序算法不是稳定的?
A. 基数排序
B. 冒泡排序
C. 选择排序
D. 归并排序
答案:C
解析:选择排序是不稳定的,如{2,2,1},第一次遍历将2与1互换,结果为{1,2,2},2与2位置互换
其余排序均是稳定的
046 在各自最优条件下,对N个数进行排序,哪个算法复杂度最低的是? ()
A. 插入排序
B. 快速排序
C. 堆排序
D. 归并排序
答案:A
解析:插入排序:最佳O(N)
快速排序:最佳O(NlogN)
堆 排序:最佳O(NlogN)
归并排序:最佳O(NlogN),因此选择插入排序。