

后端 [141]

万字详解MyBatis架构以及核心内容(2)
前言 本文讲解接口层与基础支撑层,MyBatis数据处理层,参见:《万字详解MyBatis架构以及核心内容(1)》。 接口层 接口层是 MyBatis 框架中与上层应用进行交互的关键部分,它主要由 session 模块构成,其中最为核心的是 SqlSessionFactory 和 SqlSessio

万字详解MyBatis架构以及核心内容(1)
前言 MyBatis 是一个在 Java 开发中广泛使用的持久层框架,无论是日常编程实践还是面试中,它都是一个重要的知识点。MyBatis 支持自定义 SQL、存储过程以及高级映射,为开发者提供了极大的灵活性和便利性。作为一个开源的持久化框架,它简化了与数据库交互的过程,使得开发者能够更专注于业务逻
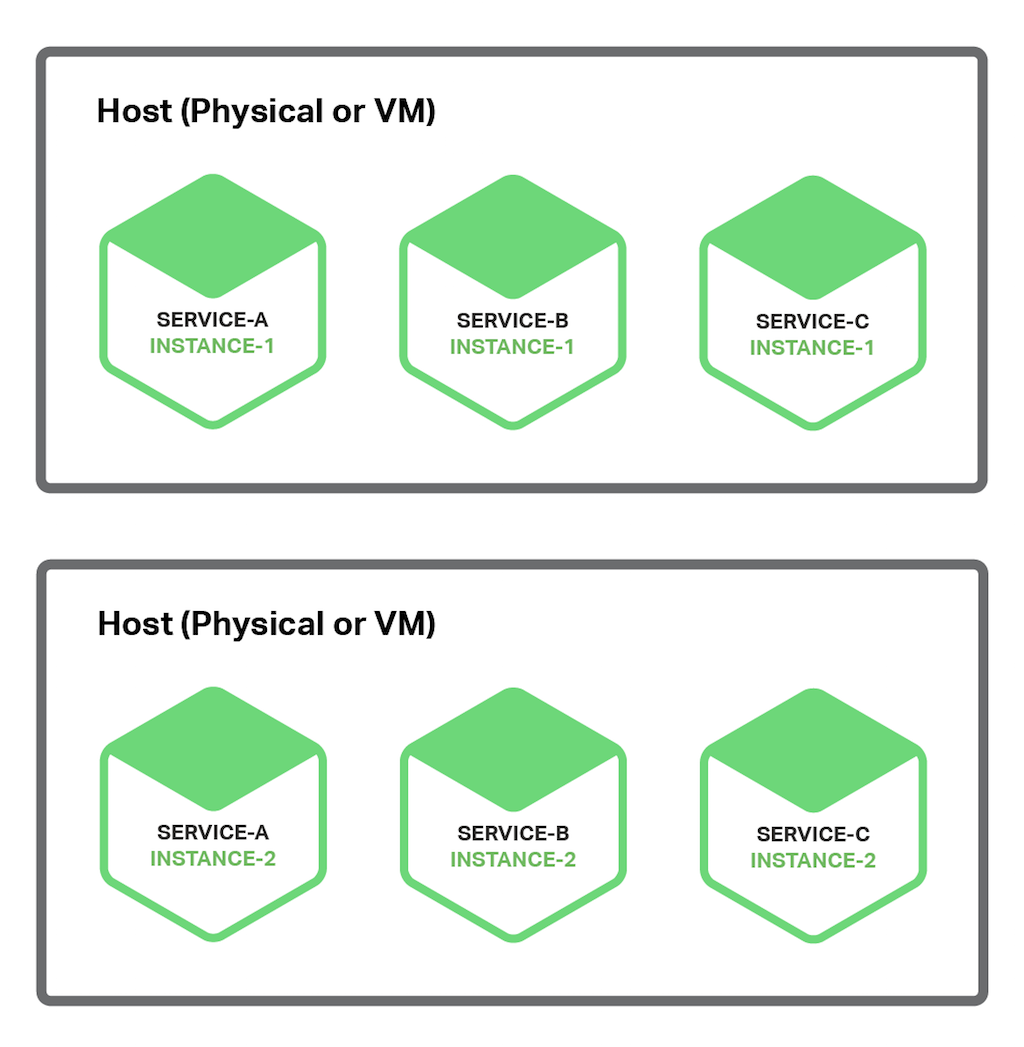

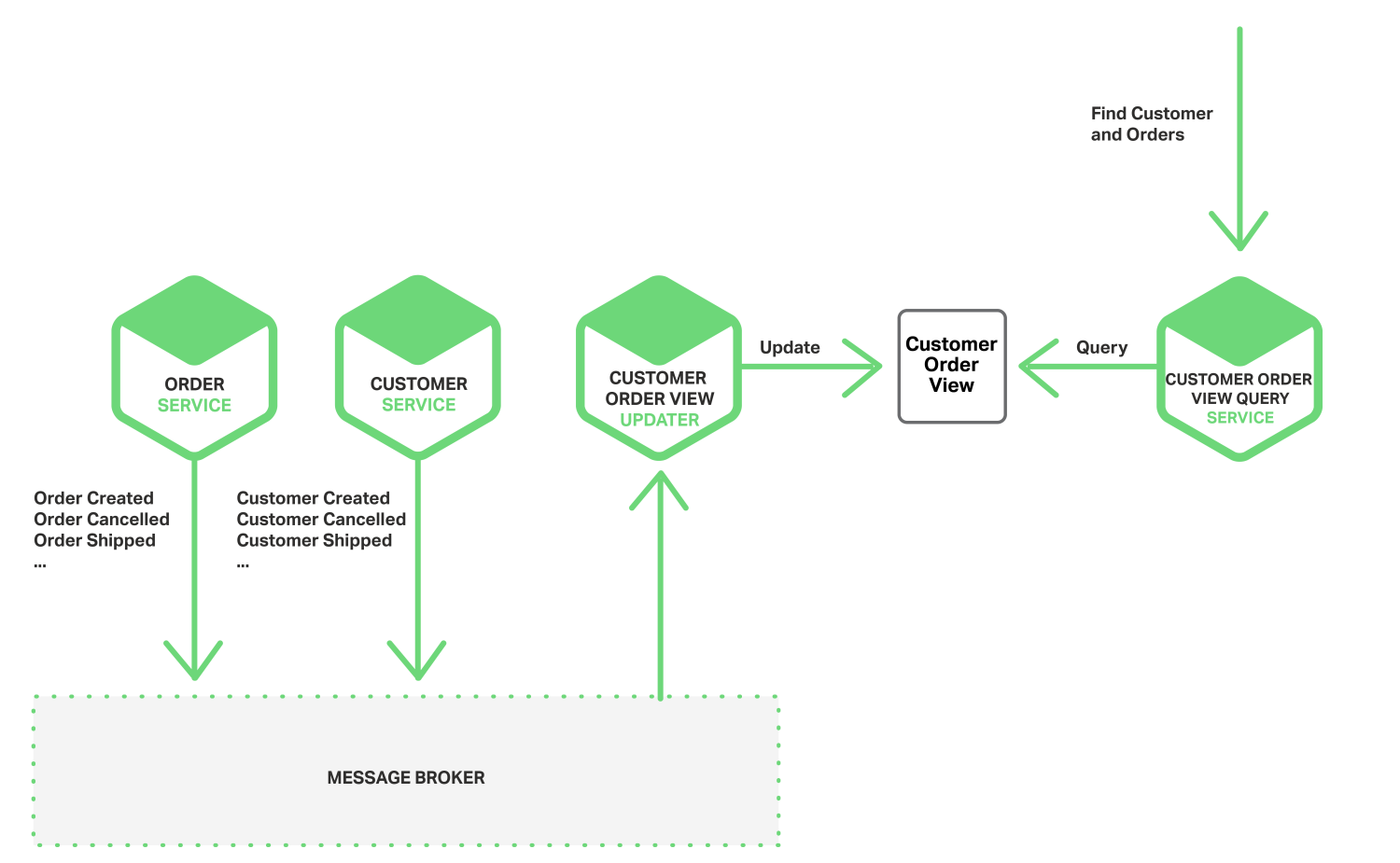
微服务的事件驱动数据管理
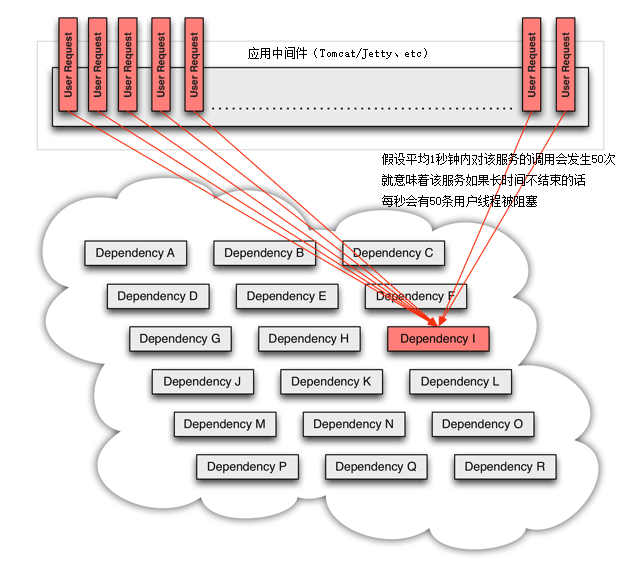
1 微服务和分布式数据管理问题 微服务架构和分布式数据管理确实带来了一系列新的挑战,尤其是在维持数据一致性和处理跨服务交易方面。在单体应用中,关系型数据库提供的ACID事务特性确保了数据的一致性和完整性,但在微服务架构中,数据通常被分散到各个服务的私有数据库中,这就需要我们重新思考数据管理和一致性的
漫谈单体应用迁移到微服务架构
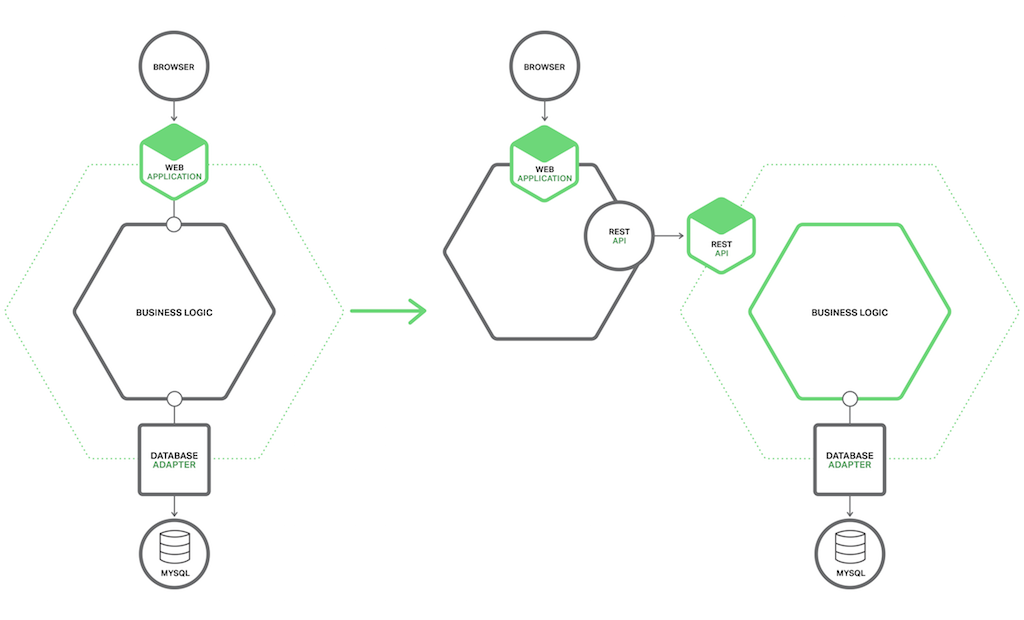
迁移单体式应用到微服务架构意味着经历一系列复杂的现代化过程,这与历代开发者持续追求技术革新的努力颇为相似。在进行迁移时,我们确实可以汲取过去的智慧并重用一些成熟的想法。 其中一个关键的策略是避免采取大规模重写代码的方式,即所谓的“大爆炸式”重写。这种方法仅在决定彻底颠覆现有系统,构建一套全新的基于微

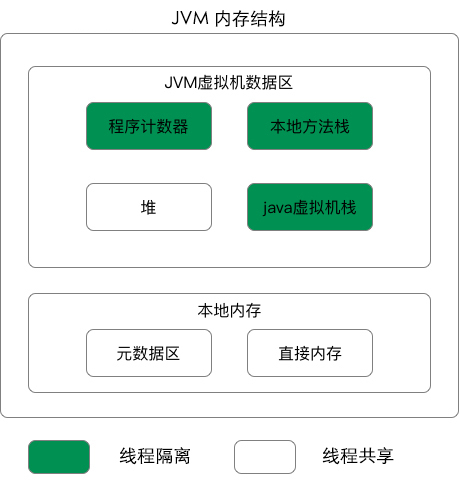
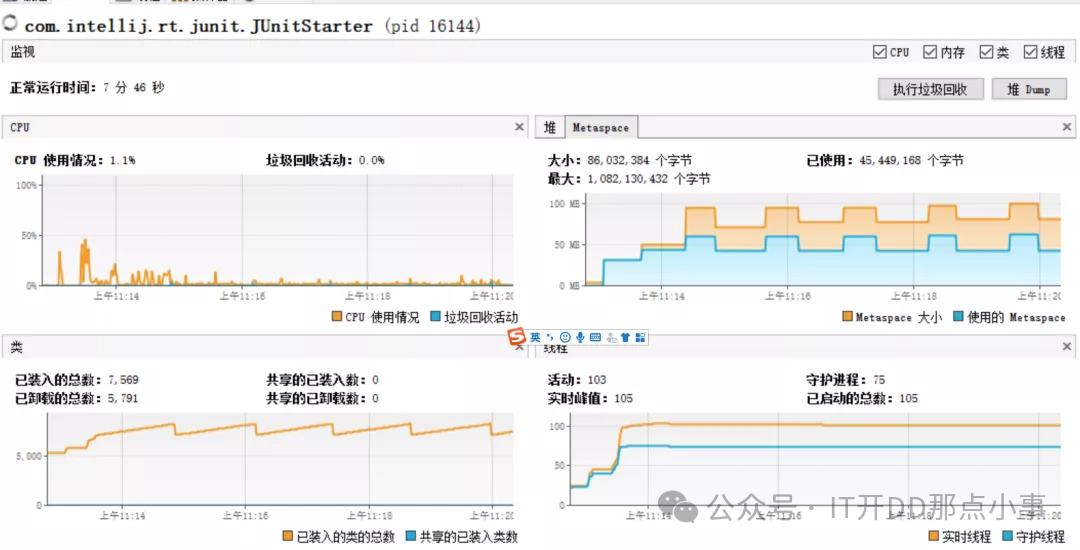
记一次完整的JVM堆外内存泄漏故障排查记录
故障描述 像是Java进程出现了内存泄漏的情况,但我们的堆内存限制为4G。由于内存占用超过了4G,可以初步判断是JVM堆外内存泄漏。 确认了下当时服务进程的启动配置: -Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=5

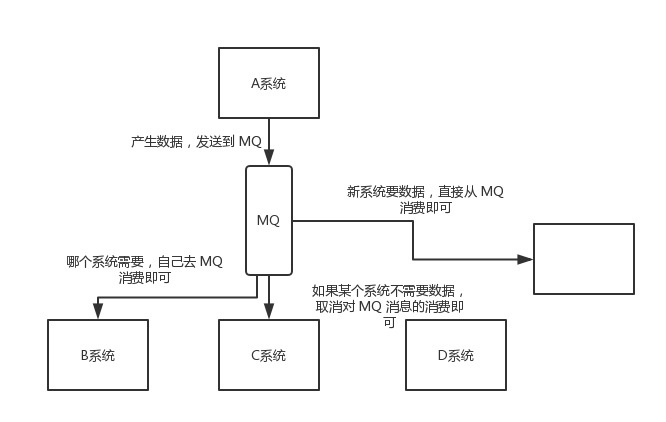
消息队列总结(精华版)
导读 为什么使用消息队列? 消息队列有什么优点和缺点? Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景? 为什么使用消息队列 消息队列作为一种重要的中间件技术,在实际项目中有着广泛的应用场景。通过解耦、异步和削峰等手段,我们可以有效解决系统中遇到的多
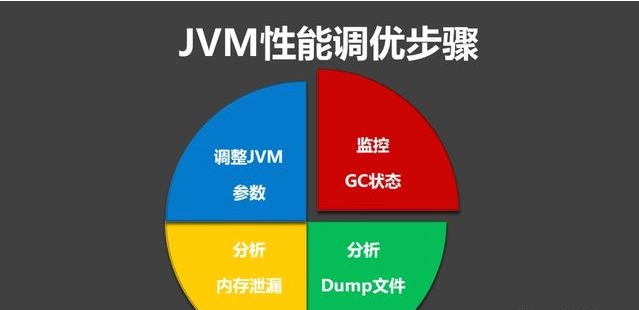
JVM内存泄露、内存溢出
内存泄露 指程序中动态分配内存给一些临时对象,但是对象不会被 GC 所回收,它始终占用内存。即被分配的对象可达但已无用。 内存溢出 指程序运行过程中无法申请到足够的内存而导致的一种错误。内存溢出通常发生于 OLD 段或 Perm 段垃圾回收后,仍然无内存空间容纳新的 Java 对象的情况。 从定义上

Netty 源码分析之环境搭建
代码下载 首先到 Netty 的 Github 仓库 中, 点击右边绿色的按钮: 拷贝 git 地址: git@github.com:netty/netty
Netty 源码分析之 Bootstrap(客户端)
这一章是 Netty 源码分析系列的第一章, 打算在这一章中, 展示一下 Netty 的客户端和服务端的初始化和启动的流程, 给读者一个对 Netty 源码有一个大致的框架上的认识, 而不会深入每个功能模块. 本章会从 Bootstrap/ServerBootstrap 类 入手, 分析 Netty
Netty 源码分析之 Bootstrap(服务端)
服务器端 在分析客户端的代码时, 已经对 Bootstrap 启动 Netty 有了一个大致的认识, 那么接下来分析服务器端时, 就会相对简单一些了. 首先还是来看一下服务器端的启动代码: public final class EchoServer {
static final boole
Netty 源码分析之 ChannelPipeline(一)
前言 这篇是 Netty 源码分析 的第二篇, 在这篇文章中, 会为读者详细地分析 Netty 中的 ChannelPipeline 机制. Channel 与 ChannelPipeline 相信大家都知道了, 在 Netty 中每个 Channel 都有且仅有一个 ChannelPipeline
Netty 源码分析之 ChannelPipeline(二)
ChannelHandler 的名字 我们注意到, pipeline.addXXX 都有一个重载的方法, 例如 addLast, 它有一个重载的版本是: ChannelPipeline addLast(String name, ChannelHandler handler);
第一个参数指定了所添