

1、资源运行情况
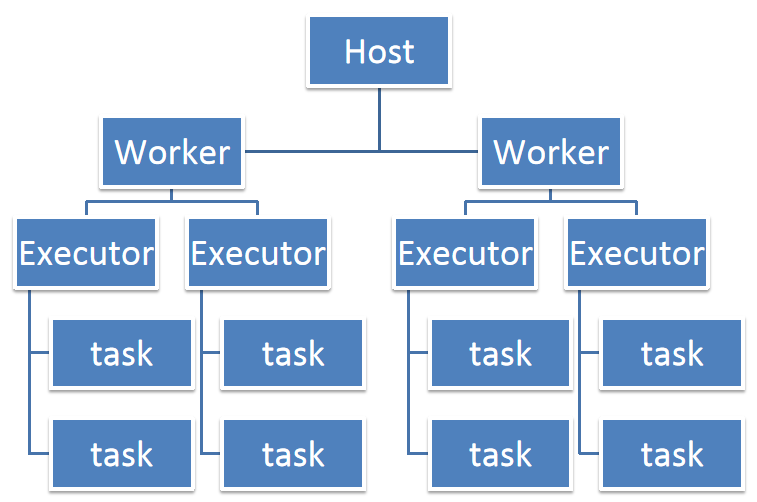
2、资源运行中的集中情况
(1)在实际运行中,我们有时会遇到Spark job执行速度异常缓慢的情况。通过检查发现,这些job的CPU利用率很低。为了改善这种情况,我们可以尝试调整资源分配策略。具体来说,可以减少每个executor占用的CPU core数量,同时增加并行的executor数量。此外,配合增加数据分片的数量,可以整体上提高CPU的利用率,从而加快数据处理的速度。
(2)另外,有些job容易发生内存溢出的问题。为了解决这一问题,我们采取了增加分片数量的策略,这样可以减少每个分片的数据规模。同时,我们还减少了并行的executor数量,使得相同的内存资源能够分配给数量更少的executor。这样做虽然可能会稍微降低运行速度,但可以有效避免内存溢出(OOM)的发生,保证job的稳定性。
(3)在处理小文件或少量数据时,有时会出现不必要的文件分片和大量小文件生成的情况。这种情况下,我们应该减少文件分片,避免创建过多的task。需要注意的是,小文件问题不仅仅出现在输入数据较小时,有时在运算过程中,如应用reduceBy或filter等操作后,数据量也可能大幅减少,导致资源利用低效。因此,我们需要密切关注运算过程中的数据变化,及时调整资源分配策略,以提高资源利用效率。
3、运行资源优化配置
在Spark作业的运行过程中,资源的优化配置是提升作业性能的关键所在。考虑到一个CPU core在同一时间内只能执行一个线程,因此为每个Executor进程分配多个task时,这些task将以多线程的方式并发运行,每个task对应一条线程。
在提交Spark应用时,我们需要合理设置应用的内存、CPU核心数和Executor数量。这些参数的选择直接关系到应用的运行效率和资源利用率。
评论