
大数据[11]
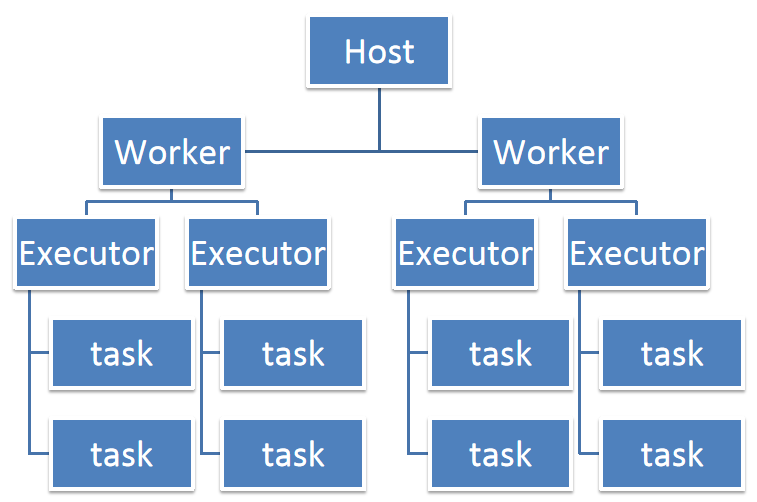
Spark运行资源调优专题
1、资源运行情况 2、资源运行中的集中情况 (1)在实际运行中,我们有时会遇到Spark job执行速度异常缓慢的情况。通过检查发现,这些job的CPU利用率很低。为了改善这种情况,我们可以尝试调整资源分配策略。具体来说,可以减少每个executor占用的CPU core数量,同时增加并行的exec


Spark程序开发调优专题
1、程序开发调优:避免创建重复的RDD 在Spark程序中,如果需要对同一份数据进行多次操作,应当尽量避免创建重复的RDD。因为每次调用textFile这样的方法都会从数据源(如HDFS)重新加载数据,并创建一个新的RDD,这会造成不必要的性能开销。 错误的做法: 在以下示例中,对同一个HDFS文件
Spark的Shuffle配置调优专题
1、Shuffle优化配置 -spark.shuffle.file.buffer 默认值:32k 参数说明: 这个参数设定了shuffle write task在将数据写入磁盘文件前所使用的BufferedOutputStream的缓冲大小。当数据写入这个缓冲区时,一旦缓冲区满,数据才会被刷新到磁盘
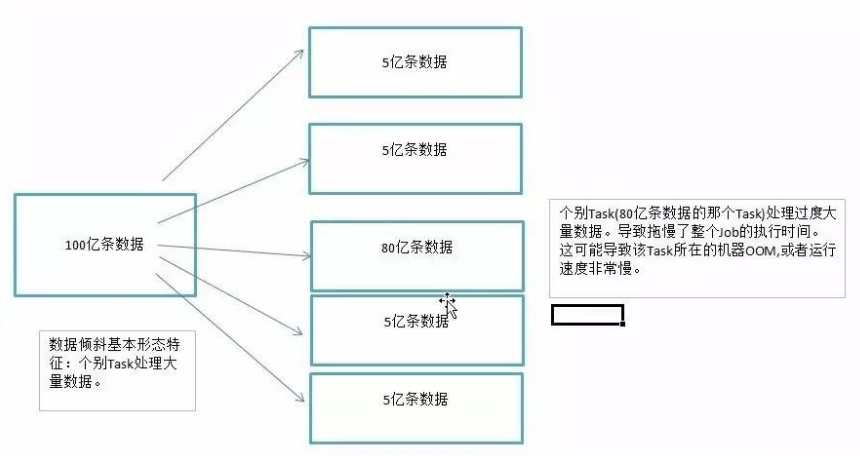
Spark数据倾斜调优专题
1、数据倾斜 数据倾斜,在并行处理数据集的上下文中,指的是数据在分布到不同处理单元(如Spark的Partition或Kafka的Partition)时,某一部分或某些部分的数据量显著多于其他部分,这种现象通常会导致该部分数据的处理成为整个处理过程的瓶颈。 数据倾斜带来的两大直接且严重的后果如下:

Flink 面试题及答案整理,最新面试题
Flink中的状态后端(State Backends)有哪些类型,它们的区别是什么? <

Spark 面试题及答案整理,最新面试题
Spark中的RDD和DataFrame的主要区别是什么? Spark中RDD(Resilient Distributed Dataset)和D
Hadoop 面试题及答案整理,最新面试题
Hadoop中的MapReduce是什么,它是如何工作的? MapReduce是Hadoop的核心组件,用于处理
2024年大数据面试的热门问题
大数据是涉及以TB或PB为单位的大型数据集的大量数据。根据一项调查,今天大约90%的数据是在过去两年中产生的。大数据帮助公司对其提供的产品和服务产生有价值的见解。近年来,每家公司都使用大数据技术来完善其营销活动和技术。对于那些对准备跨国公司大数据面试感兴趣的人来说,本文是一个极好的指南。 如何为大数

【开源分享】一系列的开源BI推荐
【开源分享】一系列的开源BI推荐 欢迎来到百战百胜!我们致力于为广大IT从业者、学生和爱好者提供全面、实用的资源和服务。加入我们的聊天群,这里有专业大佬为你提供有价值的建议和指导! 小编也是多年经验的IT从业者,有可视化方面或其他开发上的问题可以随时交流 <

【开源分享】LarkMidTable数据中台
欢迎来到百战百胜!我们致力于为广大IT从业者、学生和爱好者提供全面、实用的资源和服务。加入我们的聊天群,这里有专业大佬为你提供有价值的建议和指导! LarkMidTable

CDH6.3.1安装步骤关键记录
资源划分 192.168.56.102 cdh-test-001
192.168.56.103 cdh-test-002
192.168.56.104 cdh-test-003
关闭防火墙 systemctl stop firewalld.service
systemctl disable fir