
Spark[4]
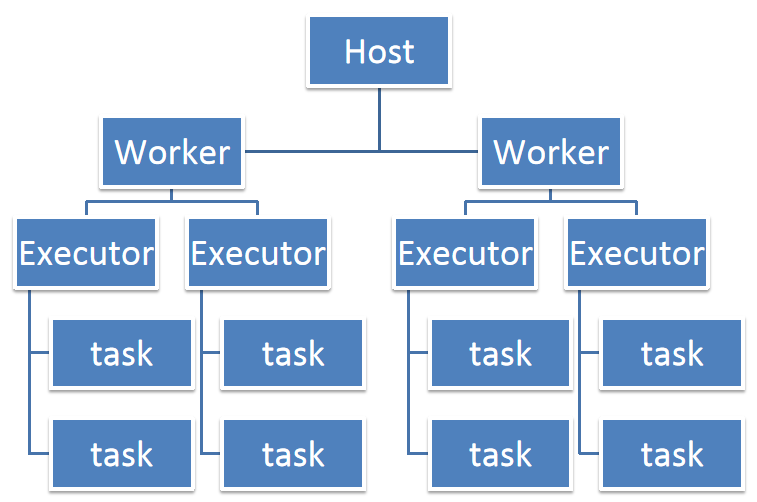
Spark运行资源调优专题
1、资源运行情况 2、资源运行中的集中情况 (1)在实际运行中,我们有时会遇到Spark job执行速度异常缓慢的情况。通过检查发现,这些job的CPU利用率很低。为了改善这种情况,我们可以尝试调整资源分配策略。具体来说,可以减少每个executor占用的CPU core数量,同时增加并行的exec


Spark程序开发调优专题
1、程序开发调优:避免创建重复的RDD 在Spark程序中,如果需要对同一份数据进行多次操作,应当尽量避免创建重复的RDD。因为每次调用textFile这样的方法都会从数据源(如HDFS)重新加载数据,并创建一个新的RDD,这会造成不必要的性能开销。 错误的做法: 在以下示例中,对同一个HDFS文件
Spark的Shuffle配置调优专题
1、Shuffle优化配置 -spark.shuffle.file.buffer 默认值:32k 参数说明: 这个参数设定了shuffle write task在将数据写入磁盘文件前所使用的BufferedOutputStream的缓冲大小。当数据写入这个缓冲区时,一旦缓冲区满,数据才会被刷新到磁盘
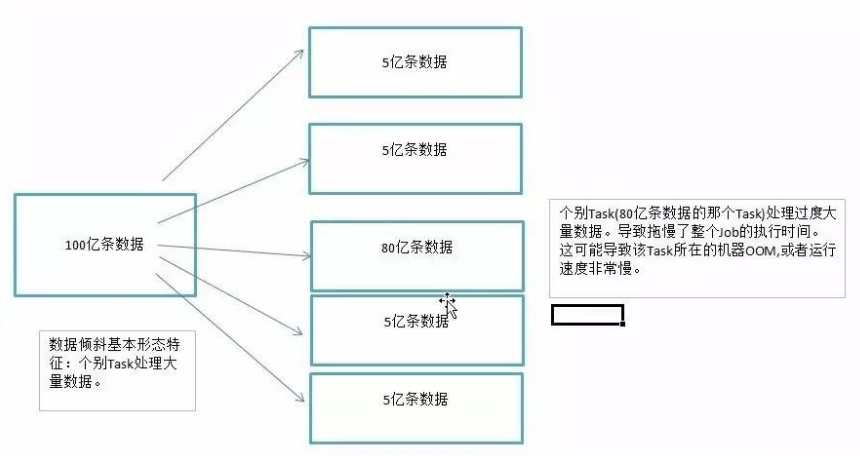
Spark数据倾斜调优专题
1、数据倾斜 数据倾斜,在并行处理数据集的上下文中,指的是数据在分布到不同处理单元(如Spark的Partition或Kafka的Partition)时,某一部分或某些部分的数据量显著多于其他部分,这种现象通常会导致该部分数据的处理成为整个处理过程的瓶颈。 数据倾斜带来的两大直接且严重的后果如下: