
















公司赠送的个人成长经费,应该怎么使用?
最近一位粉丝私信我,咨询一个问题:“公司每年提供2000元的个人成长经费,如何使用?” 借着这位粉丝的问题,以下是我的一些建议,希望更全面地利用这笔经费: 🌟参加线下研讨会或讲座 理由:关注与你所在行业或感兴趣领域相关的线下活动,如技术研讨会、行业讲座等。这些活动通常能为你提供与业内专家面对面交流

面试官:Innodb是如何实现事务的?
概述 InnoDB是MySQL数据库的一个存储引擎,它支持事务处理。事务处理是数据库管理系统执行过程中的一个逻辑单位,由一个或多个SQL语句组成,这些语句要么全部执行,要么全部不执行,是一个不可分割的工作单位。InnoDB通过以下方式来实现事务: 原子性(Atomicity): 原子性确保事务是一个

面试官:MVCC是什么?ACID靠什么保证的?
MVCC是什么 概述 全称 Multi-Version Concurrency Control,多版本并发控制。指维护一个数据的多个版本,使得读写操作没有冲突,快照读为MySQL实现MVCC提供了一个非阻塞读功能。MVCC的具体实现,还需要依赖于数据库记录中的三个隐式字段、undo log日志、re

面试官:Spring Boot如何优化并发连接数?
Spring Boot优化并发连接数是一个涉及到多个层面的任务,主要涉及到应用层面的配置优化、数据库层面的优化以及系统层面的调优。以下是一些建议的优化措施: 应用层面配置优化: 调整Tomcat参数:Spring Boot内置Tomcat作为Web容器,你可以根据需要调整Tomcat的参数来优化并发

面试官:SpringBoot如何优化启动速度?一通回答下来直接拿捏住了!!
SpringBoot优化启动速度需要从多个层面入手,包括依赖管理、Bean初始化、扫描索引、配置文件优化、日志优化以及JVM优化等。通过综合应用这些优化措施,我们可以显著提高SpringBoot应用程序的启动速度,提升用户体验和系统性能。以下是一些建议措施 常见措施 减少依赖项:Spring Boo

【开源分享】Start 6.8K,MIT协议RPA式开源爬虫平台
介绍 平台以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台 特性 支持Xpath/JsonPath/css选择器/正则提取/混搭提取 支持JSON/XML/二进制格式 支持多数据源、SQL select/selectInt/selectOne/insert/update/delete 支持爬取

【开源分享】Start 2.4K,MIT协议,开箱即用的28181协议视频平台
概述 WVP-PRO基于GB/T 28181-2016标准实现的流媒体平台,依托优秀的开源流媒体服务ZLMediaKit,提供完善丰富的功能。 GB/T 28181-2016 中文标准名称是《公共安全视频监控联网系统信息传输、交换、控制技术要求》是监控领域的国家标准。大量应用于政府视频平台。

【开源分享】Start 12.1K,一个MIT协议的流媒体框架
项目特点 基于C++11开发,避免使用裸指针,代码稳定可靠,性能优越。 支持多种协议(RTSP/RTMP/HLS/HTTP-FLV/WebSocket-FLV/GB28181/HTTP-TS/WebSocket-TS/HTTP-fMP4/WebSocket-fMP4/MP4/WebRTC),支持协议
【开源分享】Start 15.4k,业内最流行的零代码平台之一
项目介绍 JeecgBoot 是一款基于代码生成器的低代码开发平台!前后端分离架构 SpringBoot2.x,SpringCloud,Ant Design&Vue,Mybatis-plus,Shiro,JWT,支持微服务。强大的代码生成器让前后端代码一键生成,实现低代码开发! JeecgBoot


【开源分享】Start 5.5k,开源界国内统一身份认证第一IAM
MaxKey概述 开源地址:👇👇👇文末 MaxKey单点登录认证系统,谐音为马克思的钥匙寓意是最大钥匙,是业界领先的IAM-IDaas身份管理和认证产品;支持OAuth 2.x/OpenID Connect、SAML 2.0、JWT、CAS、SCIM等标准协议;提供安全、标准和开放的用户身份管

阅读+分享,一起往“钱”冲
为感谢广大粉丝朋友一直以来对【IT开DD那点小事】公众号的支持与喜爱,我们特别策划了一场名为【阅读+分享,一起往“钱”冲】的感恩回馈活动。 活动规则: 我们将依据微信公众号后台的精确统计数据,每周一筛选出阅读榜和分享榜的前三名,共计6位幸运粉丝。这6位粉丝将获得我们精心准备的微信红包奖励,以表达我们
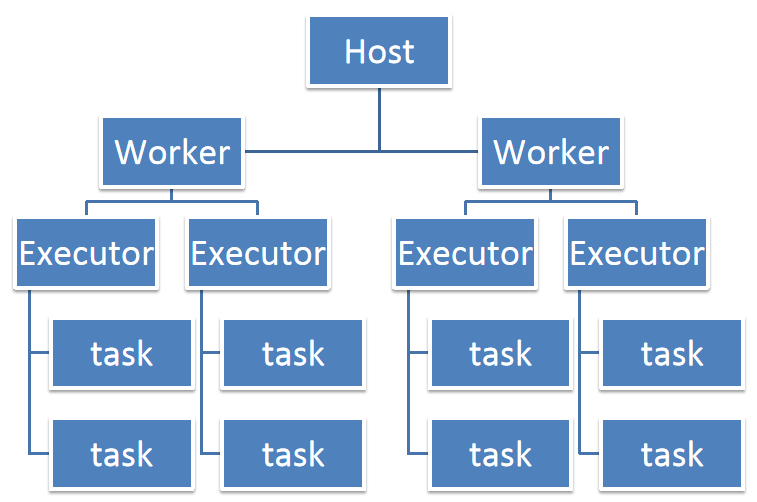
Spark运行资源调优专题
1、资源运行情况 2、资源运行中的集中情况 (1)在实际运行中,我们有时会遇到Spark job执行速度异常缓慢的情况。通过检查发现,这些job的CPU利用率很低。为了改善这种情况,我们可以尝试调整资源分配策略。具体来说,可以减少每个executor占用的CPU core数量,同时增加并行的exec

Spark程序开发调优专题
1、程序开发调优:避免创建重复的RDD 在Spark程序中,如果需要对同一份数据进行多次操作,应当尽量避免创建重复的RDD。因为每次调用textFile这样的方法都会从数据源(如HDFS)重新加载数据,并创建一个新的RDD,这会造成不必要的性能开销。 错误的做法: 在以下示例中,对同一个HDFS文件
Spark的Shuffle配置调优专题
1、Shuffle优化配置 -spark.shuffle.file.buffer 默认值:32k 参数说明: 这个参数设定了shuffle write task在将数据写入磁盘文件前所使用的BufferedOutputStream的缓冲大小。当数据写入这个缓冲区时,一旦缓冲区满,数据才会被刷新到磁盘
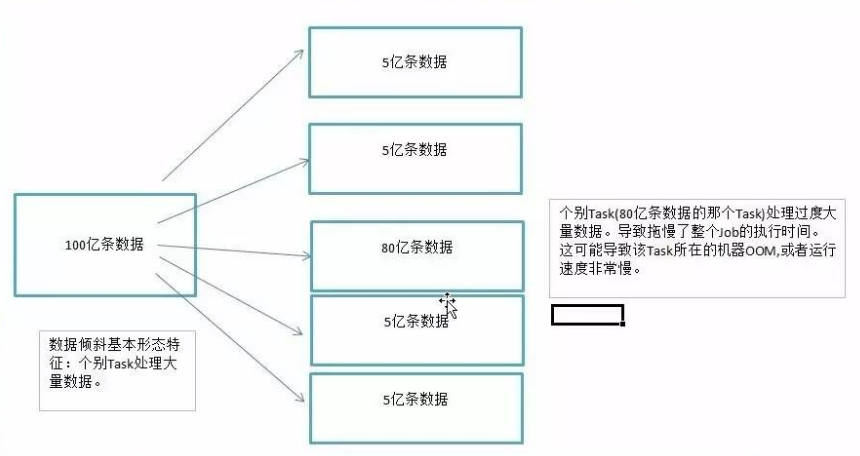
Spark数据倾斜调优专题
1、数据倾斜 数据倾斜,在并行处理数据集的上下文中,指的是数据在分布到不同处理单元(如Spark的Partition或Kafka的Partition)时,某一部分或某些部分的数据量显著多于其他部分,这种现象通常会导致该部分数据的处理成为整个处理过程的瓶颈。 数据倾斜带来的两大直接且严重的后果如下: