

面试 [279]

面试官:Spring Boot如何优化并发连接数?
Spring Boot优化并发连接数是一个涉及到多个层面的任务,主要涉及到应用层面的配置优化、数据库层面的优化以及系统层面的调优。以下是一些建议的优化措施: 应用层面配置优化: 调整Tomcat参数:Spring Boot内置Tomcat作为Web容器,你可以根据需要调整Tomcat的参数来优化并发

面试官:SpringBoot如何优化启动速度?一通回答下来直接拿捏住了!!
SpringBoot优化启动速度需要从多个层面入手,包括依赖管理、Bean初始化、扫描索引、配置文件优化、日志优化以及JVM优化等。通过综合应用这些优化措施,我们可以显著提高SpringBoot应用程序的启动速度,提升用户体验和系统性能。以下是一些建议措施 常见措施 减少依赖项:Spring Boo
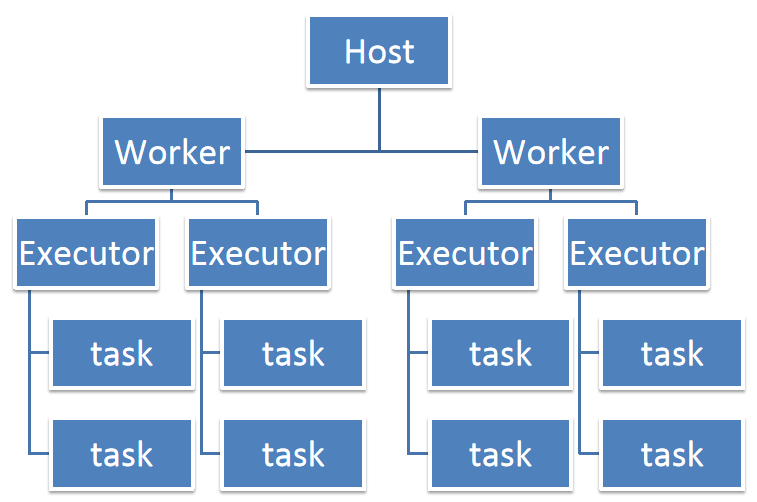
Spark运行资源调优专题
1、资源运行情况 2、资源运行中的集中情况 (1)在实际运行中,我们有时会遇到Spark job执行速度异常缓慢的情况。通过检查发现,这些job的CPU利用率很低。为了改善这种情况,我们可以尝试调整资源分配策略。具体来说,可以减少每个executor占用的CPU core数量,同时增加并行的exec


Spark程序开发调优专题
1、程序开发调优:避免创建重复的RDD 在Spark程序中,如果需要对同一份数据进行多次操作,应当尽量避免创建重复的RDD。因为每次调用textFile这样的方法都会从数据源(如HDFS)重新加载数据,并创建一个新的RDD,这会造成不必要的性能开销。 错误的做法: 在以下示例中,对同一个HDFS文件
Spark的Shuffle配置调优专题
1、Shuffle优化配置 -spark.shuffle.file.buffer 默认值:32k 参数说明: 这个参数设定了shuffle write task在将数据写入磁盘文件前所使用的BufferedOutputStream的缓冲大小。当数据写入这个缓冲区时,一旦缓冲区满,数据才会被刷新到磁盘
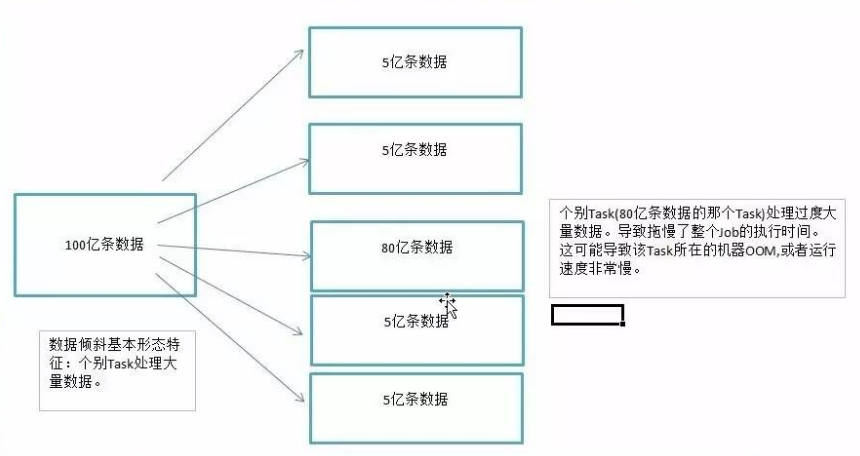
Spark数据倾斜调优专题
1、数据倾斜 数据倾斜,在并行处理数据集的上下文中,指的是数据在分布到不同处理单元(如Spark的Partition或Kafka的Partition)时,某一部分或某些部分的数据量显著多于其他部分,这种现象通常会导致该部分数据的处理成为整个处理过程的瓶颈。 数据倾斜带来的两大直接且严重的后果如下:

面试官:线上项目JVM怎么设置?
面试官心里剖析 当面试官询问关于线上JVM(Java虚拟机)的设置时,他们通常想了解你对JVM调优、内存管理、垃圾回收等方面的理解和实践经验 回答思路 1. 堆内存设置 假设有一个电商网站,它需要在高峰时段处理大量的用户请求和交易数据。为了保证应用的稳定运行,我会根据服务器的物理内存大小以及应用的内
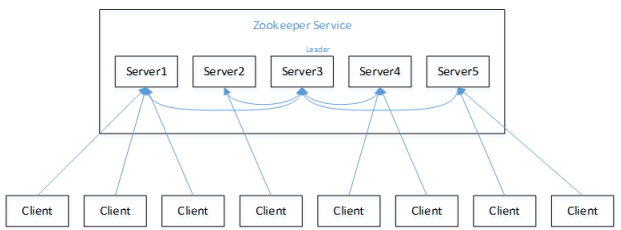
ZooKeeper的10道经典面试题
1、Zookeeper选举机制 假设我们有一个由五台服务器组成的ZooKeeper集群,这些服务器的ID分别是1到5。这些服务器都是全新启动的,没有历史数据,因此在存放数据量的初始状态上,它们都是相同的。现在,我们按照ID的顺序依次启动这些服务器,让我们看看会发生什么。 (1)当服务器1启动时,由于

面试官:服务限流方案有哪些?怎么实现的?
题目剖析 生活中的遇到哪些突发流量? 双11、618大促 电商秒杀活动 微博突发新闻 …… 什么是限流? 通常我们说的限流指的是限制达到系统的并发请求数 ,使得系统能够正常的处理<

面试官:分布式事务了解吗?你们是如何解决分布式事务问题的?
面试题 分布式事务了解吗? 你们是如何解决分布式事务问题的? 面试官心理分析 在面试中,分布式事务往往是一个必问的问题,因为它直接关联到系统的数据一致性和业务逻辑的正确性。 面试题剖析 分布式事务的实现主要有
面试官:redis分布式锁与zk分布式锁的区别
面试题 使用 Redis 如何设计分布式锁? 使用 zk 来设计分布式锁可以吗? 这两种分布式锁的实现方式哪种效率比较高? 面试官心理分析 必考题,聊到分布式,都会问到以上问题。 面试题剖析 Redis 分布式锁 RedLock

面试官:你负责项目的时候遇到了哪些比较棘手的问题?怎么解决的
面试官心理剖析 面试官在询问程序员关于项目中遇到的棘手问题及其解决方案时,其实是在进行多方面的考察,这背后蕴含着一些特定的心理活动和考量因素。 探查你是小白或者只是个CRUD程序员 如果你回答我在项目中没有怎么遇到比较棘手的问题,那么面试官会觉得你要么是小白什么都不会,要么还是只个CRUD程序员没有
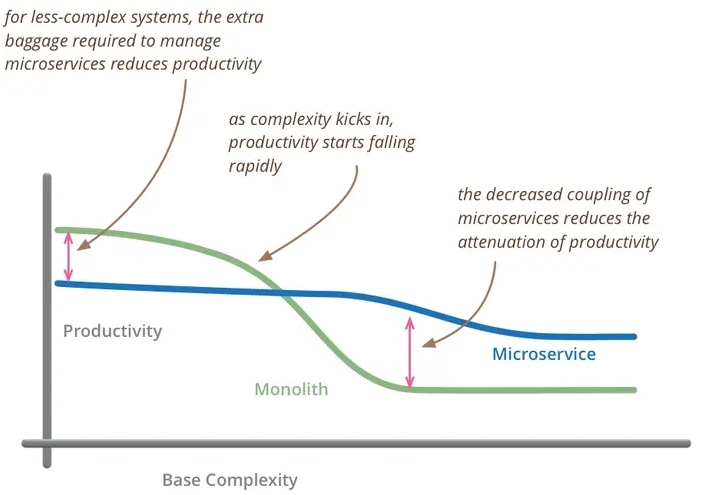
系统拆分之道(面试版)
导读 分布式系统成为行业标配的演变 系统拆分的必要性及其优势 如何进行系统拆分? 分布式系统成为行业标配的演变 步入现今的IT界,我们不难发现分布式系统已逐渐成为面试的必备话题。简历上若缺乏相关经验,几乎难以获得面试机会。这种趋势的背后,其实是大行业技术发展的必然结果。
字节跳动2024最新招聘
字节跳动校招:https://jobs.bytedance.com/referral/campus/pc/position 字节跳动社招:https://jobs.bytedance.c

米哈游 2024 最新招聘信息
米哈游校招:https://jobs.mihoyo.com/#/campus/position 米哈游社招:

拼多多2024届校园招聘-菁越计划-多多买菜校招项目
网站地址:https://careers.pinduoduo.com/campus/grad/local

拼多多2024届校园招聘-管培生招聘
网站地址:https://careers.pinduoduo.com/campus/grad

拼多多2025届校园招聘-研发实习生
网站地址:https://careers.pinduoduo.com/campus/intern